# 机器学习课程-李宏毅
youtube课程地址 (opens new window)
# 机器学习的基本概念
1-5 Supervised Learning
6 生成式对抗网络 Generative Adversarial Network
7 自监督学习 self-supervised Learning
BERT 基础模型
8 异常检测 Anomaly Detection
9 可解释性AI Explainable AI
10 模型攻击 Model Attack
11 领域适应 Domain Adaptation
12 强化学习 Reinforcement Learning
13 模型压缩 Network Compression
14 终身机器学习 Life-long Learning
15 元学习-学习如何学习 Meta learning
google colab
浅谈机器学习原理

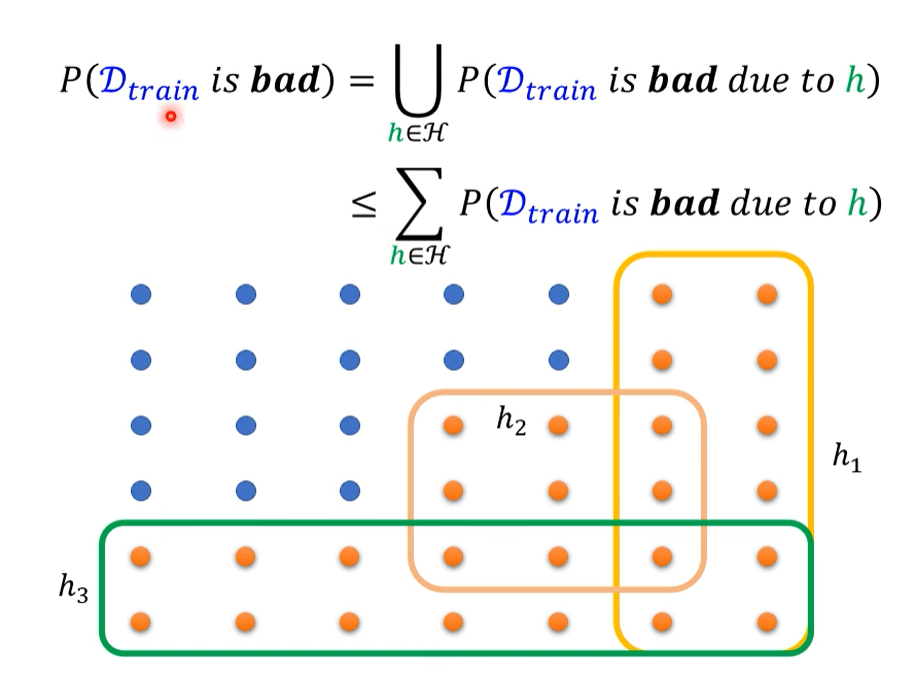


VC-dimension 描述一个模型复杂程度的指标

structure learning 让机器产生有结构的输出
机器学习公式推导比较难的一步是计算梯度, 而pytorch框架可以自动计算梯度。
# 机器学习任务攻略
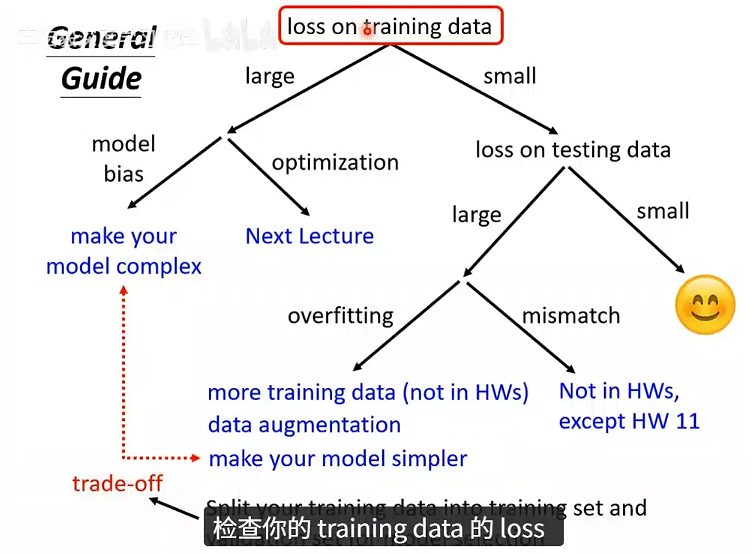
当LOSS比较大的时候,可能是模型偏差,也可能是优化没做好,怎么判断呢?
- 使用容易优化的浅层的网络,或者其他的模型
- 如果更深的模型在训练数据上没有获得更小的loss,那就是优化没做好
深层网络一定可以做到浅层网络做到的事情,比如50层的网络,前20层可以和20层的网络做相同的事情,后30层什么也不做,那50层的网络效果和20层的网络就是一样的。
# 过拟合问题
过拟合问题解决方案
- 增加训练数据
- 数据增强:比如图像领域机器学习,可以把图片左右翻转,部分放大
- 给模型一些限制:少的参数,共用参数
- 更少的要素
- 正则化
- Early stopping:在验证集性能达到最优时,提前停止训练
- Dropout
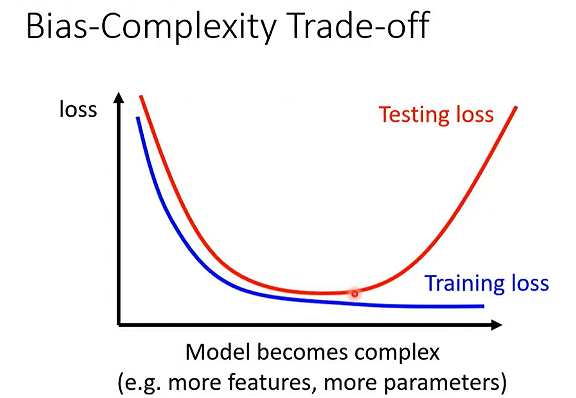
模型太简单会有模型偏差,模型过于复杂会过拟合。
# 模型泛化能力
公共测试集:比赛开发阶段用于评估模型性能的测试数据
私有测试集:比赛最终阶段(盲测阶段)使用的隐藏测试数据
因此需要把训练数据集分为两部分,一部分用于训练,一部分用于验证。选择验证集上LOSS最小的模型就好。
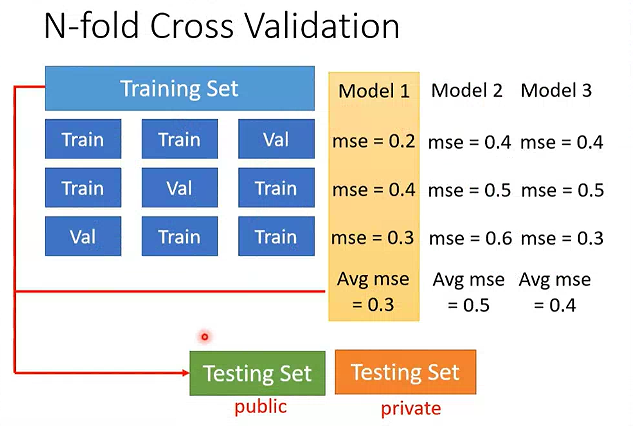
# n 折交叉验证
用于评估模型的泛化能力
将整个数据集随机且均匀地划分为 n 个互斥的子集(称为 fold,即 “折”),然后重复 n 次训练和验证:
- 每次选取 1 个 fold 作为验证集,剩下的 n-1 个 fold 作为训练集;
- 用训练集训练模型,用验证集计算性能指标(如准确率、Loss);
- 完成
n次循环后,取 n 次验证指标的平均值,作为模型的最终评估结果。
mismatch:分布偏移或模型不匹配。模型的训练逻辑是架设训练数据和测试数据服从相同的概率分布,一旦这个架设不成立,模型学到的规律就无法适配测试数据。
# 鱼和熊掌可以兼得
传统的机器学习中,模型越复杂,越容易过拟合,模型越简单,泛化能力越强,但无法处理复杂任务。
深度学习可以同时兼顾高模型容量(捕捉复杂模式的能力)和强泛化能力(适配新数据的能力)
# 模型优化
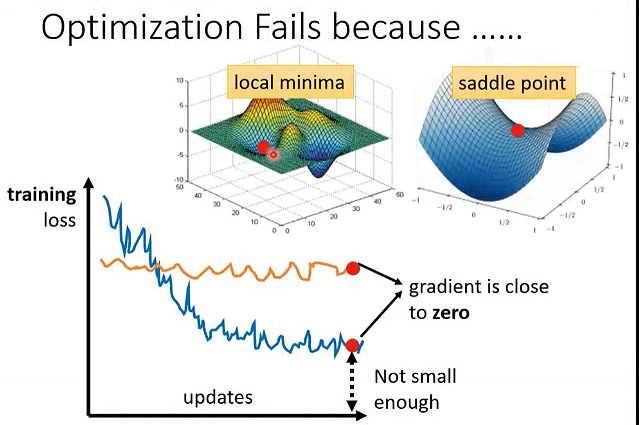
# 鞍点、局部最小、局部最大
当梯度为0时,不一定是局部最小值,也有可能是鞍点。
用泰勒展开计算:

H是海森矩阵,多元函数的的二阶偏导数方阵,可以使用海森矩阵正负定性判断极值点。
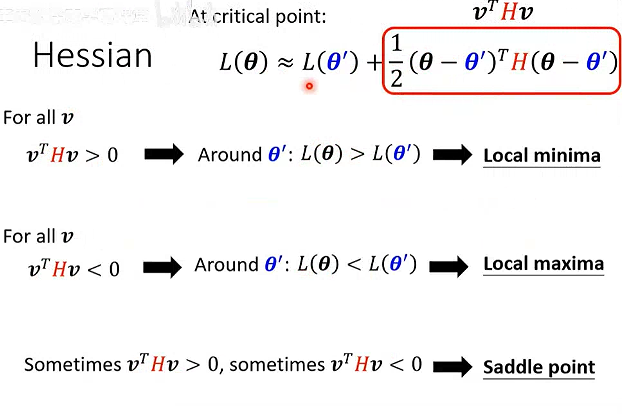
正定矩阵:实对称矩阵所有特征值大于0,称为正定矩阵。
海森矩阵的特征值有正有负,表示该点是鞍点。
沿着
负特征值对应的特征向量方向更新参数,可以降低LOSS。
二维的局部最小值在三维看来可能是一个鞍点,低维度看起来无路可走,在高维度其实是有路的。
# 批次和动量
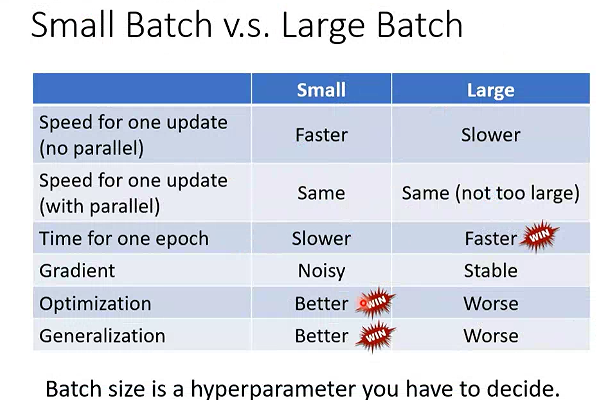
为什么要用batch?
当并行计算时,较大的batch size计算梯度时不一定比小的batch size 花的时间长。
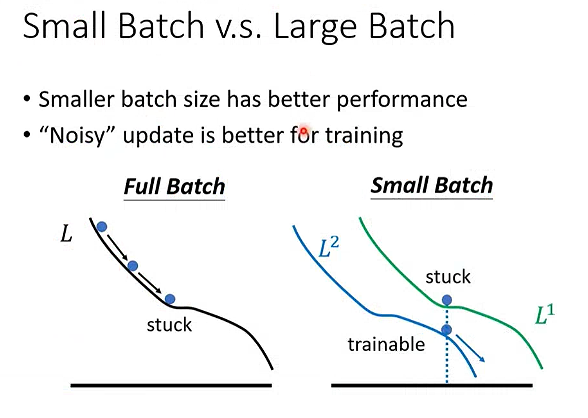
小的batch size 在优化和测试集上效果更好。
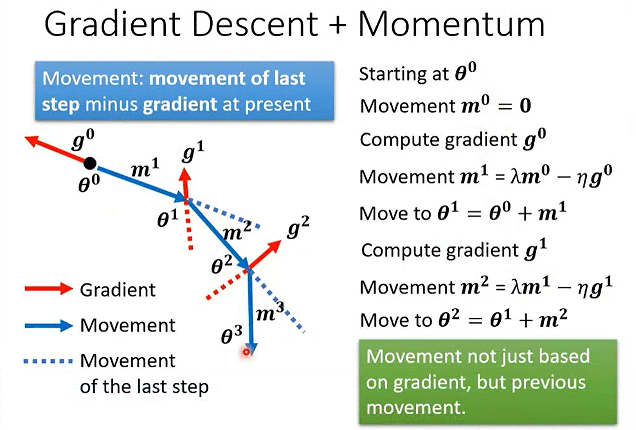
动量Momentum
梯度下降法:每次朝着梯度的反方向更新一步。
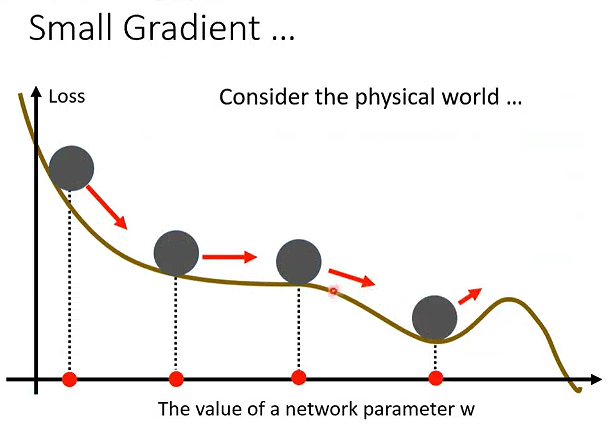
然而,在物理世界中,小球沿着Loss函数滚落,由于带有速度,不会在局部最小值停下。
动量只是类比物理世界中物体运动惯性的特点。
考虑动量的计算:每一步的变化量=上一步的变化量-当前步的梯度
引入动量有什么好处?
- 加速收敛速度
- 抑制参数更新震荡
- 突破局部极小值或鞍点
# 自动调整学习率
当Loss不再减小的时候,并不意味着梯度一定很小,有可能在Minima附近震荡。
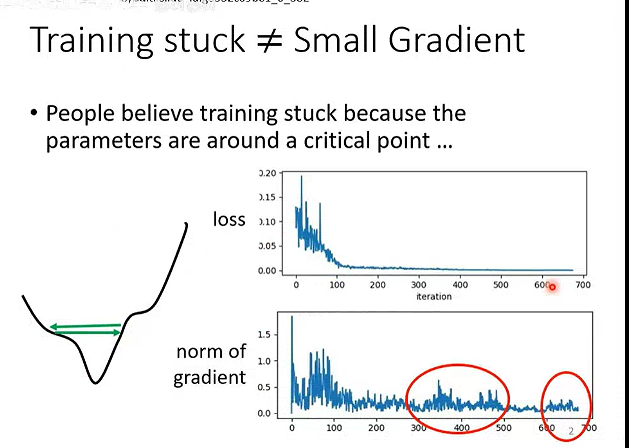
为什么需要自适应学习率?
固定学习率无法适配复杂误差曲面的不同区域,容易导致收敛慢、震荡或不收敛。
哪里难走,就放慢脚步;哪里好走,就加快速度
# 典型的自适应算法
Adagrad算法:累积参数的历史梯度平方和
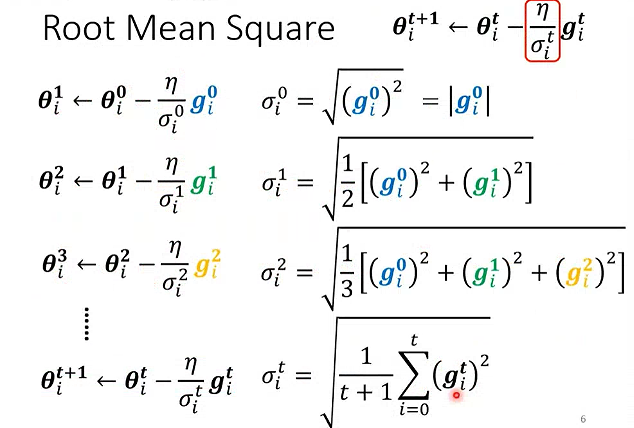
RMSprop:指数移动平均累积梯度平方和
衡量近期梯度的波动幅度,远期的梯度影响会指数级衰减。
衰减系数α通常取0.9
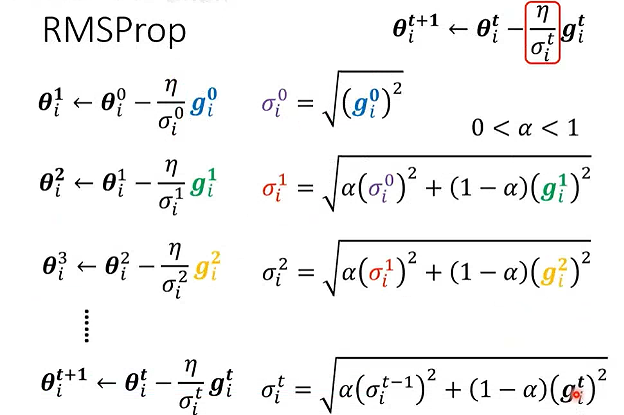
Adam:结合动量 + RMSprop 的思想
# 学习率调度
Learning Rate Decay:学习率衰减
初期学习率较大,末期学习率较小。
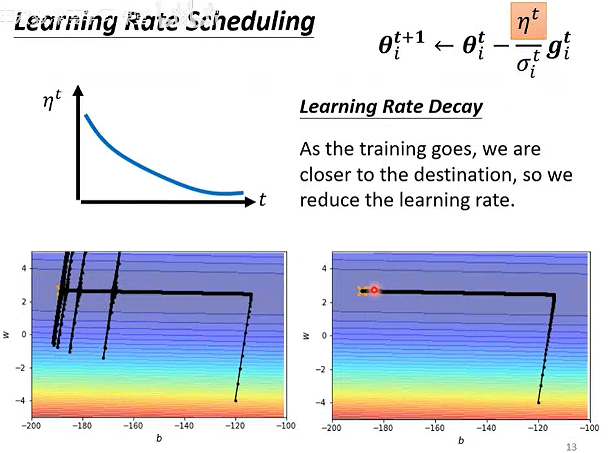
Warm Up:学习率先变大、后变小
在很多知名的网络都有使用。
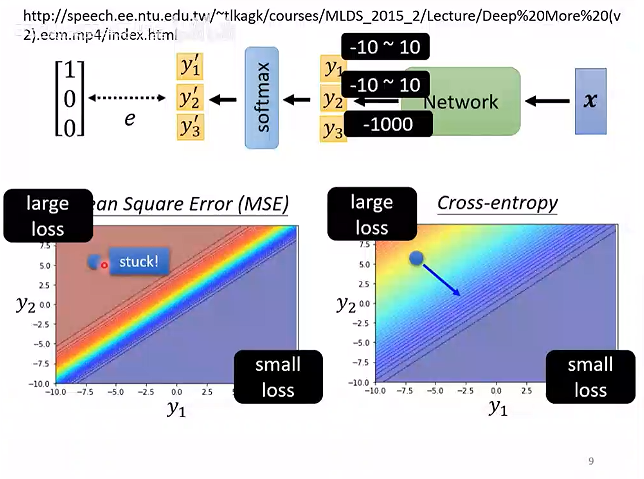
# 不同的损失函数Loss
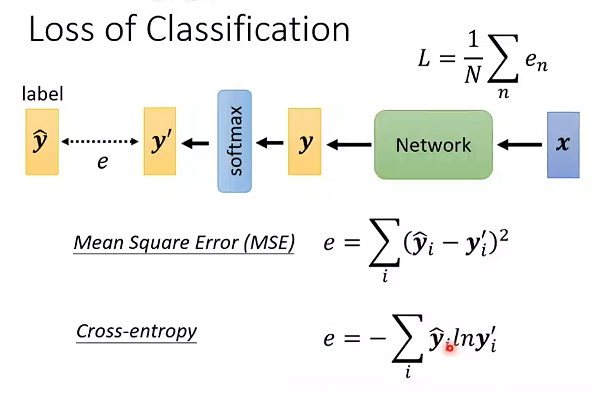
交叉熵最小等价于最大似然
交叉熵通常用于分类任务。
# 卷积神经网络CNN
图像识别的卷积核一般是3×3, 加深层数后仍然可以识别更大形状的pattern
图像是一个三维的tensor,三个维度分别是图像的宽、高、通道数
过滤器:用相同的一组卷积核扫过整个图像,这个卷积核可以认为是一个过滤器。每一层的过滤器可以有很多个。对应下一层图像的通道数。
池化操作:在保留核心特征的情况下,对特征图进行降维(减小尺寸)。(最大池化、平均池化)
原始图像-卷积-池化-卷积-池化-flatten-全连接层-softmax
如果算力足够,也可以不用做池化
案例:下围棋其实是一个分类问题,可以用CNN解决,19×19的棋盘,通道就是该位置的状态。
Alfgo使用的网络架构:19×19×4,卷积核是5×5,边缘补0,步长为1,192个filter,没有用池化。
CNN不能处理影响放大、缩小、旋转的问题。
Special Tranformer Layer可以处理放大、缩小、旋转的问题
今年来,CNN也用在语音和图像上,但是网络设计、卷积核设计是不一样的。
# 注意力机制
# Sequence Labeling
输入是一堆向量,而且长度不一,通过word embedding给每个词汇一个向量。例如:
- 文字处理
- 语音识别
- 分子结构式
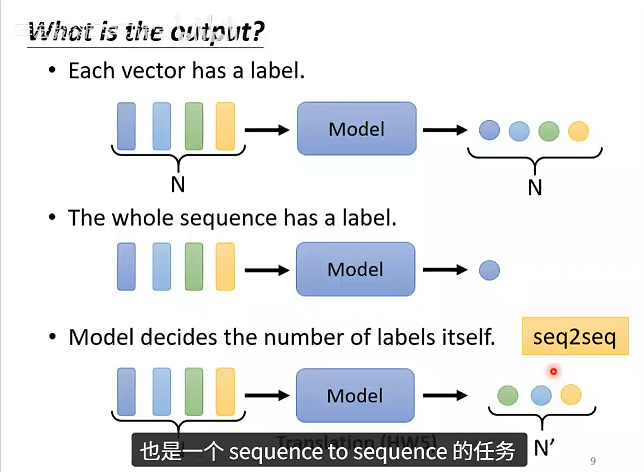
输出类型:
- 每个向量输出一个label
- 整个序列输出一个label
- 机器自己决定输出几个label(seq2seq)
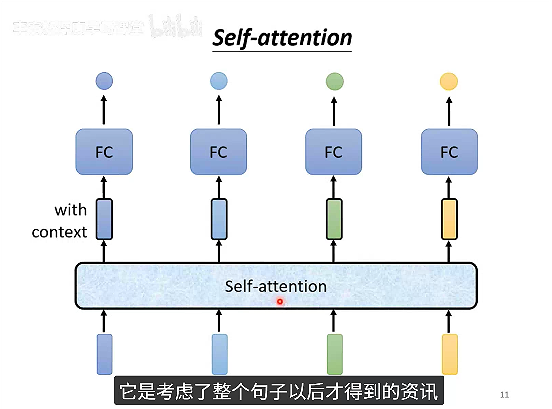
考虑上下文
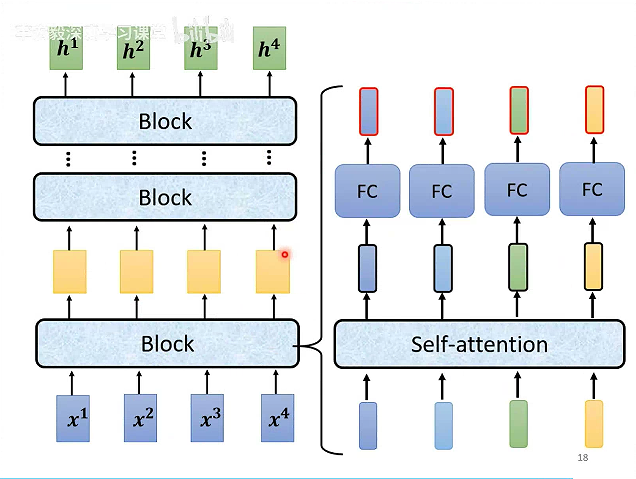
# Self-attention
每个输出向量都考虑一整个sequence的信息。可以作为层,可叠加。
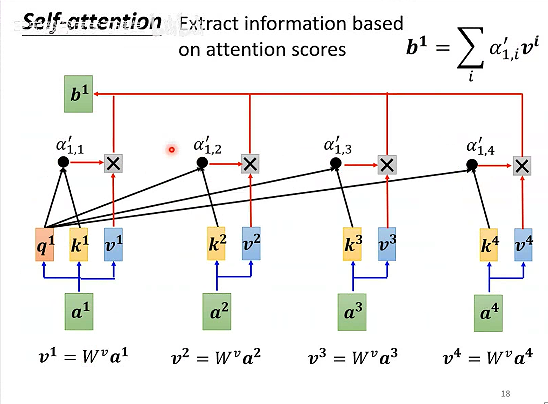
如何计算Self-attention的输出元素b1?
计算输入a1和其他输入元素的相关性。
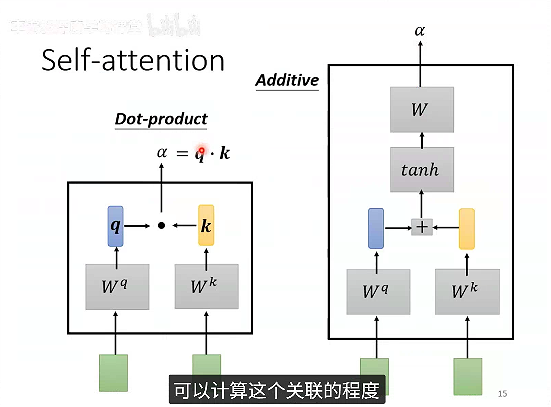
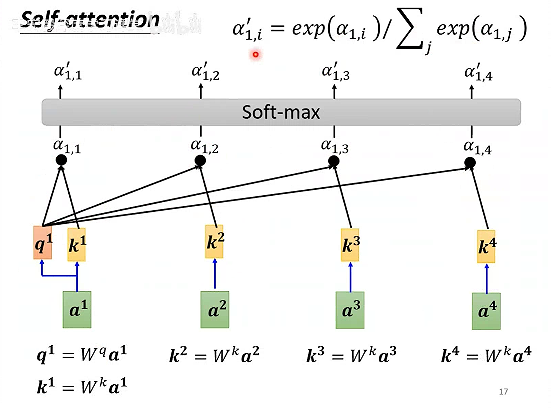
如何计算相关性α呢?
计算输入a1的q1矩阵和a1-a4对应的k矩阵的点乘,得到a1和a1-a4的相关性,然后计算softmax。
于是知道了哪些向量和a1是最有关系的。
a1-a4每个向量都乘以W得到对应的v,将每个v乘以α后求和得到b1。
b1-b4可以并行计算
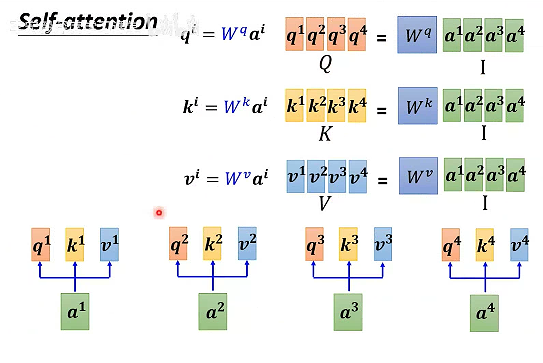
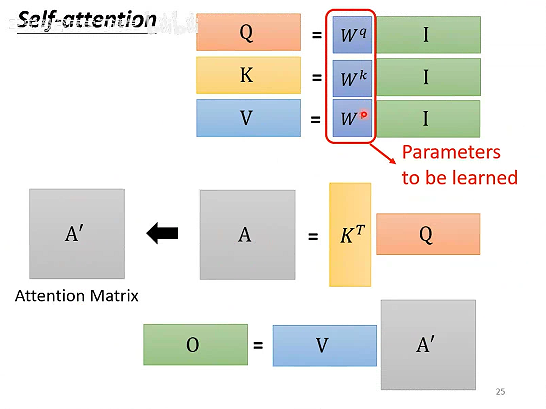
# 矩阵乘法的角度理解
把输入的a1-a4分别乘以Wq、Wk、Wv,
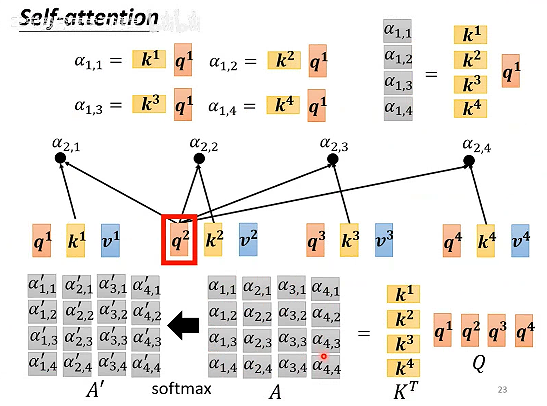
每一个α,都由对应的q和k的转置相乘得到,将k的列向量组合后转置,乘以q的列向量组合,得到相关性a的矩阵,随后进行正规化。
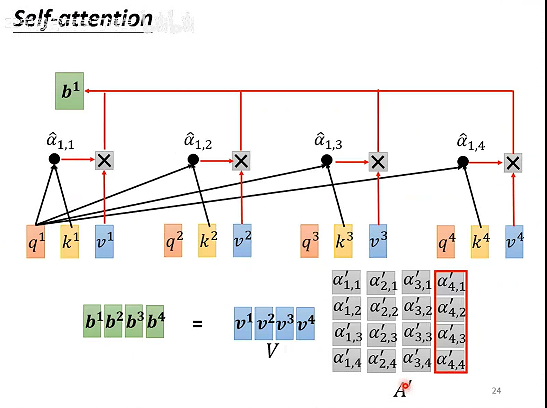
b1就相当于v的列向量组成的矩阵左乘α1的列向量,将b1-b4组合起来就得到self-attention的输出
self-atention中需要学习的参数,就只有Wq、Wk、Wv
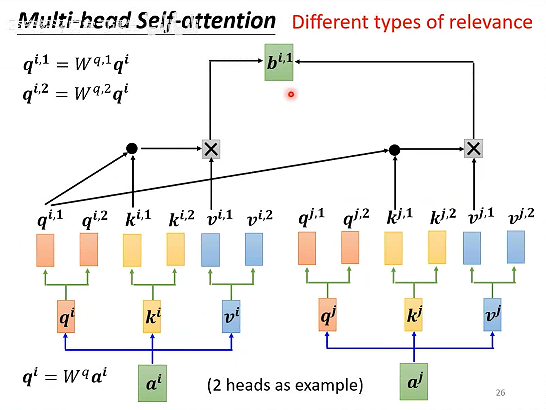
# 多头注意力机制
相关性的定义可以有很多种不同的形式,a和b可以在不同层面都具有相关性。
比如说苹果和樱桃,都是水果,也都是红色的
所谓的多头注意力,就是每个输入a都有多组对应的qkv,每一组计算得到b后,再乘以一个矩阵得到输出结果。
多组的qkv,由原始的qkv分别乘以一个矩阵得到。
自注意力机制没有位置信息
positional encoding
# 应用
self-attention被广泛用于NLP,例如transformer、Bert
其他的领域:语音识别,影像处理
Self-attention vs CNN
CNN是简化版的self-attention。
self-attention弹性比较大,训练资料比较少的时候,容易过拟合
CNN弹性比较小,训练资料少的时候效果比较好
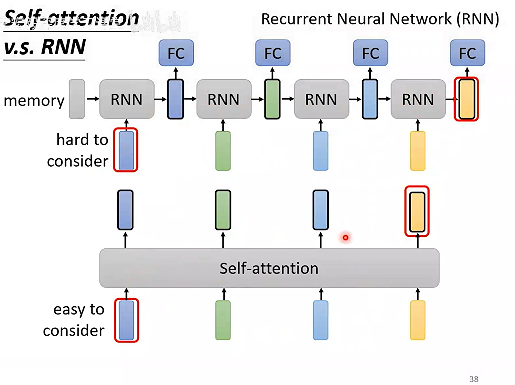
Self-attention vs RNN
RNN序列末端的输出较难考虑到序列最开始的输入,除非将最开始的输入信息保存,传递下去。
SA没有这个问题,不管序列多长,只要有相关性,就能关联到。
RNN没法并行处理,SA可以并行处理。
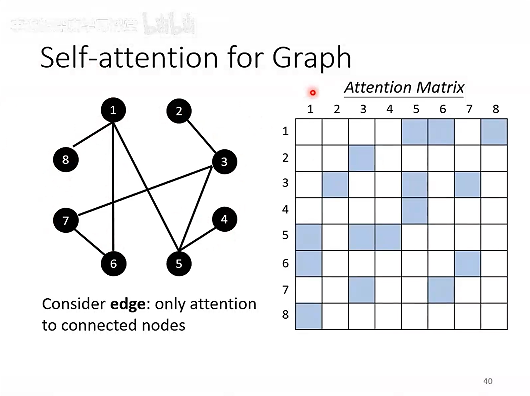
Self-attention for Graph:GNN(Graph Neural Networrk)
Self-attention的变形后来都命名为XXformer
# Batch Normalization
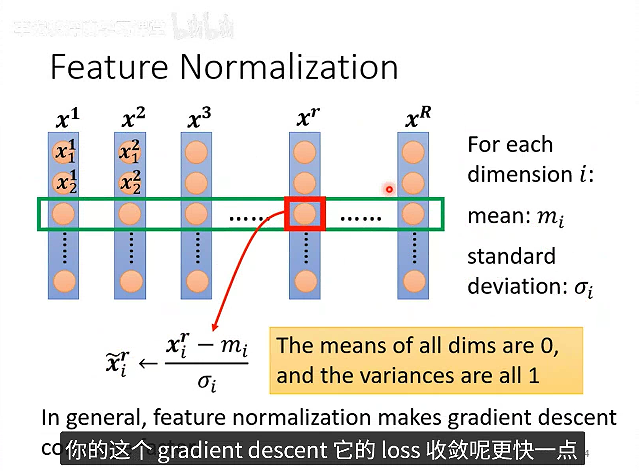
Batch Normalization是对不同数据相同维度的数据进行归一化。
为什么要做数据标准化?
核心原因是数据的不同维度有不同的数值范围,对相同的权重变化量贡献差异较大,导致在不同维度上Loss的收敛速度不同。
数据标准化就是把一组数据限制在0-1之间,同时保留数据的分布特征。
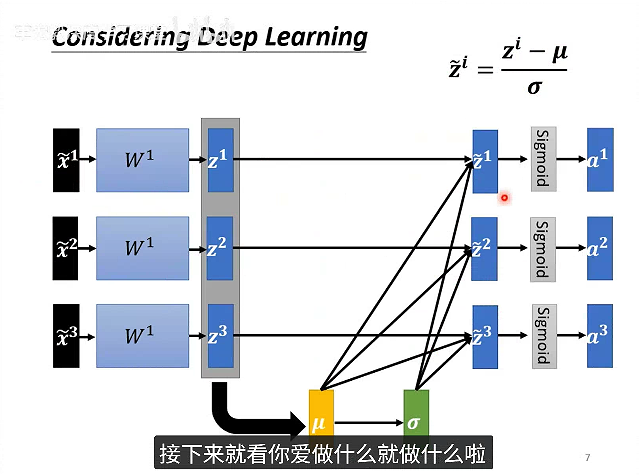
数据结果z同样做标准化,这样做之后,a1 a2 a3 就产生了相关性,改变z1,就会改变μ和σ,从而改变a1 a2 a3的值。
为什么要做批处理?
因为数据了太大了,无法一次性把所有数据放到内存里。
测试环节通常要对每一笔资料都产生一个输出,而不是等到攒够一个batch,但是没有一个batch就没有μ和σ,pytorch会在训练的时候通过移动平均自动帮我们计算。
# Transformer
# Sequence-to-sequence(Seq2seq)
从序列到序列的机器学习,通常是不清楚会有几个输出,输出的数量由机器决定。
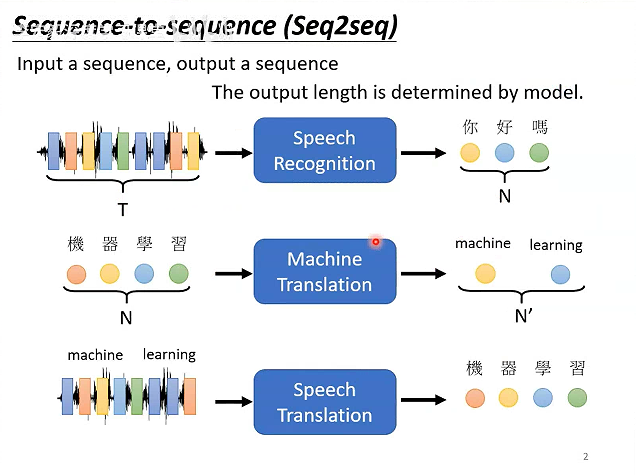
多数的NLP任务都可以使用sequence-to-sequence模型,类似于瑞士军刀,可以用在各种场景,但是针对特定的场景设计客制化模型,效果会更好一点。
seq2seq应用
Multi-class Classification 有多个分类
Multi-label Classification 同一个东西可以属于多个分类
甚至目标检测
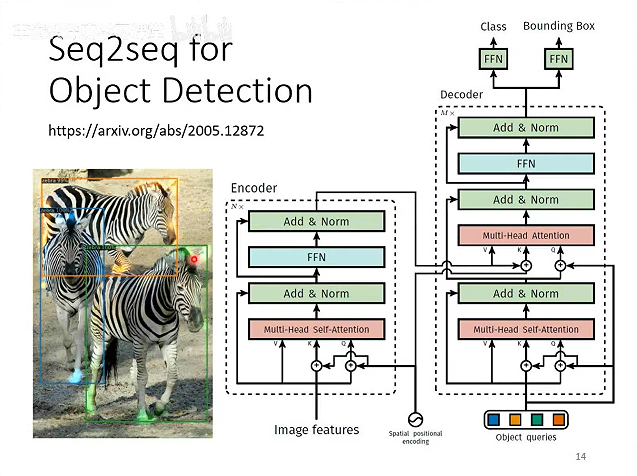
# Encoder-Decoder
Encoder输入一排向量输出另一排向量。
residual(残差网络):输入和输出加起来作为输出。可以缓解梯度消失和爆炸。
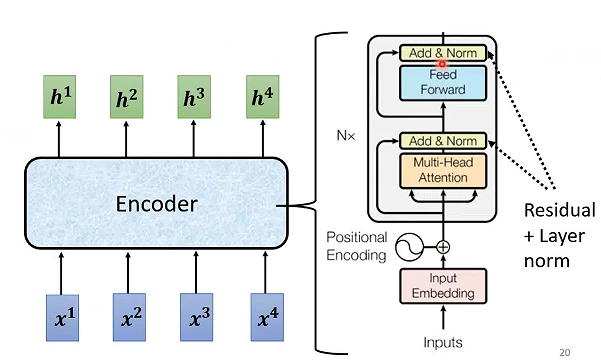
Add&Norm就是先将输入和输出相加,然后做归一化。
Bert就是transformer的Encoder
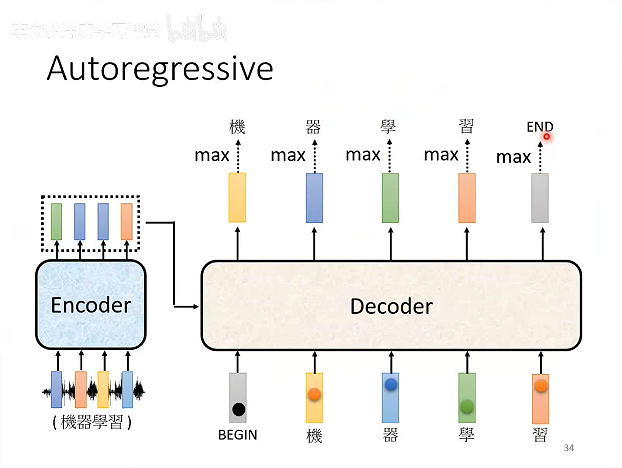
Decoder把自己每一步的输出当作下一步的输入。
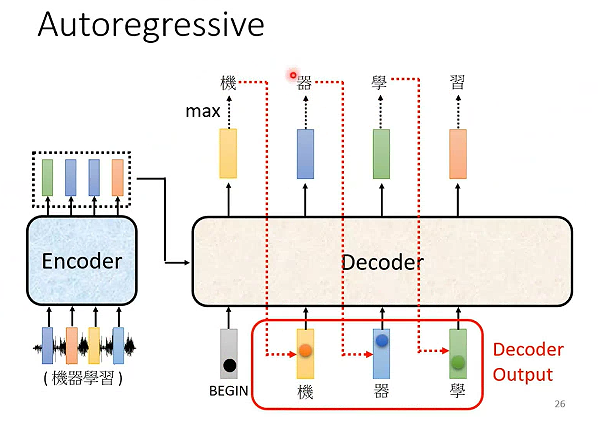
AT Decoder:自回归解码器,生成第 t 个 token 时,严格依赖前 t - 1 个已生成 token,通过循环迭代方式逐一生成完整序列,直至输出结束符。
NAT Decoder:打破 token 间的依赖关系,可一次性并行生成所有目标 token,无需等待前序 token 生成,大幅提升推理效率。
# transformer架构
transformer架构之前,就已经有seq2seq和Encoder-Decoder了,它的创新点在于引入了attention机制。
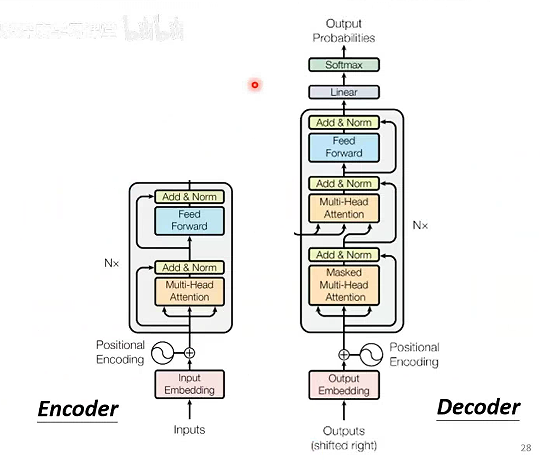
Masked Multi-Head Attention:原始的自注意力模型每个输出b都考虑到了每个输入a,加了掩膜就是每个bi只能看到ai及之前的输入。
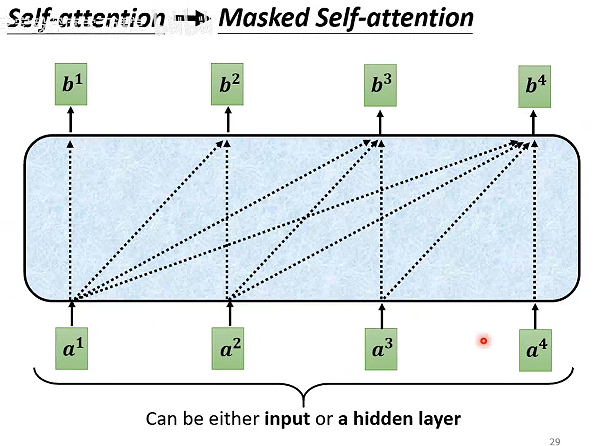
为什么需要masked?
答:输出是依次产生的,先a1,再a2,然后是a3 a4。
Decoder需要自己决定输出的长度。
添加一个End词汇,当输出End时,Decoder就不再输出。
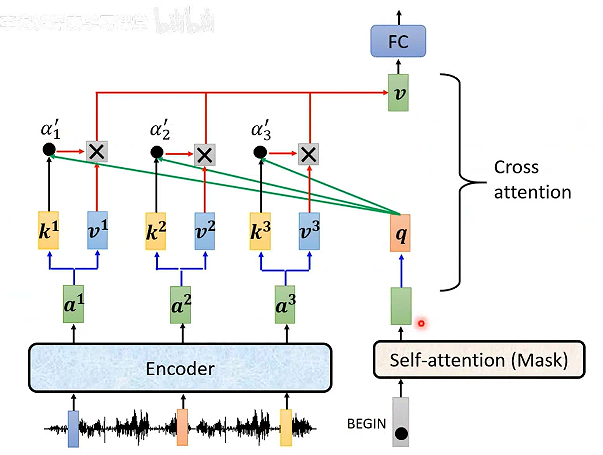
Decoder如何获取Encoder的输入呢?
Cross-Attention:q来自Decoder,kv来自Encoder
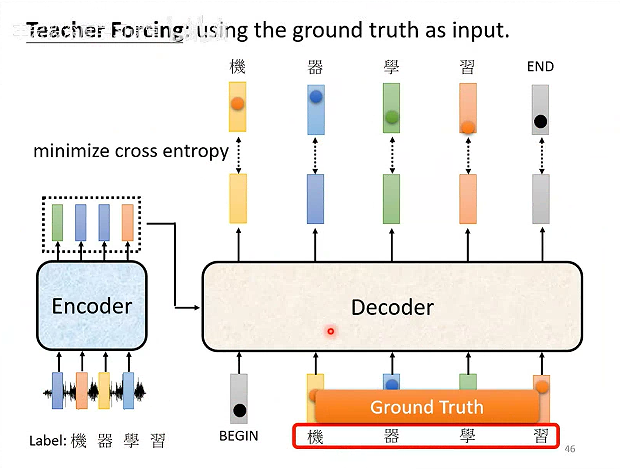
# Training
怎么训练呢?
在Decoder训练的时候,输入的时候给正确答案。
Copy Mechanism:复制机制

需要百万篇文章的训练,机器才能说合理的句子。
Guided Attention:要求机器做attention的时候有固定的方式。例如语音合成任务,序列的训练过程,有左向右。
Beam Search:核心目标是在保证生成效率的前提下,找到质量较高的输出序列,是自回归(AT)解码器的核心解码策略之一。
当一个任务答案很明确是,BS比较有用。需要发挥一点创造力的时候,BS就没用了。
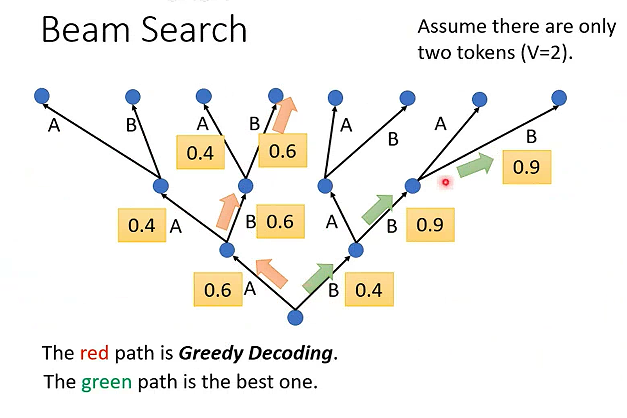
BLEU score?
# 问题总结
# 为什么用了验证集,结果还是过拟合呢?
其实用验证集来挑模型的过程,也可以看做是在训练
# 名词术语
Model Bias:模型偏差,衡量模拟拟合能力不足的指标
piecewise linear :分段线性
Loss:损失函数 means how good a et of values is .
epoch:计算梯度下降时,当所有的batch都计算一遍,作为一个epoch
update:每一次计算batch,更新参数,叫做update
hyperparameter: 超参数,机器学习中非机器自动计算的,人为设定的参数,比如batchsize,学习率等等
sigmoid函数
ReLU函数(Rectified Linear Unit):修正线性单元
Nerual Network:神经网络
Overfitting:过拟合,在训练资料上变好,在测试资料上变差的情况
benchmark corpora:基准语料库,是自然语言处理(NLP)领域中,用于评估模型性能、对比不同算法效果的标准化数据集。
critical point :临界点
error surface:误差曲面,损失函数关于参数的多维曲面。
cross-entropy:交叉熵,衡量两个概率分布的差异程度,用一个 “预测分布” 去编码一个 “真实分布” 所需的平均比特数。
交叉熵的值越小,说明预测分布 Q 和真实分布 P 越接近,模型预测越准确;
交叉熵的值越大,说明两个分布差异越大,模型预测误差越大。
Exposure Bias(暴露偏差):序列生成模型(如机器翻译、文本摘要、语音合成、轨迹预测的自回归模型)在训练和推理阶段输入分布不一致导致的一种固有缺陷,会直接影响生成序列的质量和稳定性.