# SpringBoot集成ElasticSearch
# ElasticSearch
# 概述
Doug Cutting开发了Lucene,全文搜索引擎
谷歌文件系统GFS,用于存储海量数据
MapReduce模型,用于大规模数据集并行分析计算
加盟yahoo后,Doug Cutting 将NDFS和Mapreduce进行升级改造重新命名位Hadoop
BigTable分布式数据存储系统,列存储。Doug Cutting开发了Hbase
# Lucene和ElasticSearch的工具
Lucene是一套信息检索工具包!jar包,不包含搜索引擎系统
包含:索引结构、读写索引工具、排序,搜索规则...工具类
ElasticSearch基于Lucene做了一些封装和增强
# ES和Solr的差别
Solr是Apache下的一个顶级开源项目,采用Java开发,是基于Lucene的全文搜索服务器,提供了比Lucene更为丰富的查询语言,同时可配置,可扩展,并对索引,搜索性能进行优化。
总结:
- es开箱即用,solr安装复杂一点
- solr利用zookeeper进行分布式管理,es自身带有分布式协调管理功能
- solr支持更多数据格式json、XML、CSV等等,es只支持json
- solr官方提供的功能更多,es本身更注重与核心功能,高级功能有许多第三方插件,例如图形界面需要kibana支持
- solr查询快,更新索引慢,用于电商等查询多的应用
- es建立索引快,实时查询快,用于facebook新浪等搜索
- solr是传统搜索应用的有力解决方案,es更适用于实时搜索应用
- solr比较成熟,有更大更成熟的用户,es相对较少,更新太快
# kibana
kibana是一个针对es的开源分析和可视化平台,用来搜索、查看交互存储在es索引中的数据
# 文档地址
ElasticSearch中文文档 (opens new window)
# ElasticSearch安装
# Windows安装
# 下载
从华为云镜像下载,或者从官网
ElasticSearch: https://mirrors.huaweicloud.com/elasticsearch/?C=N&O=D
logstash: https://mirrors.huaweicloud.com/logstash/?C=N&O=D
kibana: https://mirrors.huaweicloud.com/kibana/?C=N&O=D
# 修改配置文件
jvm.options 考虑电脑本身性能
-Xms256m 初始堆内存大小
-Xmx256m 最大堆内存大小
# 启动
命令行进入bin目录
运行elasticsearch.bat
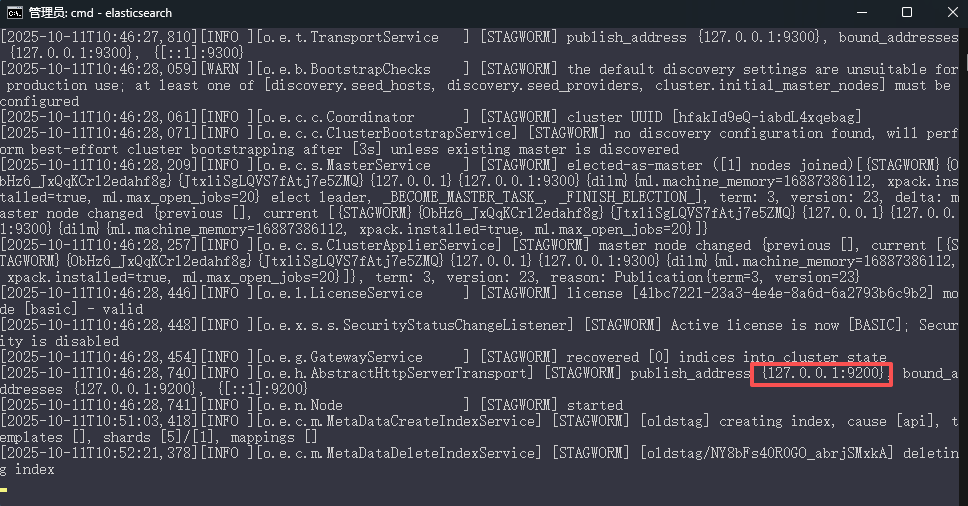
# 访问测试
http://127.0.0.1:9200/
{
"name" : "STAGWORM",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "hfakId9eQ-iabdL4xqebag",
"version" : {
"number" : "7.6.1",
"build_flavor" : "default",
"build_type" : "zip",
"build_hash" : "aa751e09be0a5072e8570670309b1f12348f023b",
"build_date" : "2020-02-29T00:15:25.529771Z",
"build_snapshot" : false,
"lucene_version" : "8.4.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
# 安装es head
安装可视化界面 es head插件,是一个开源项目
1、下载地址https://github.com/mobz/elasticsearch-head
2、npm 安装依赖,包安装不上可能是网络问题
3、运行程序 npm run start
4、 访问管理地址http://localhost:9100/,
这时候有跨域问题,不能直接访问到es的9200服务
在elasticsearch.yml中配置
http.cors.enabled: true
http.cors.allow-origin: "*"
重启es服务器,再次连接

初学把索引当作数据库!
5、 es head 当作数据展示工具,后面所有的查询用kibana
# Linux安装
# kibana安装
1、 下载
kibana版本要和es一致 前文使用7.6.1 现在也一样
下载windows版本,解压zip,进入bin目录,运行kibana,默认目录是5601
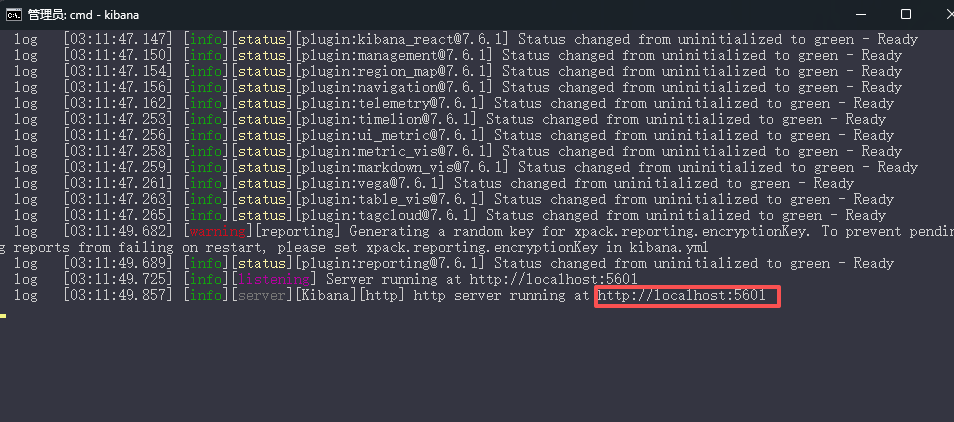
2、kibana 界面默认为英文,修改配置文件为中文
打开config/kibana.yml,修改配置
i18n.locale: "zh-CN"
重启项目
3、打开项目http://localhost:5601
# ES核心概念
集群:由一个或者多个es节点组成集合,共同存储数据,处理请求
节点:运行中的单个es实力
索引:类似关系型数据库的“数据库”,具有相似文档结构的集合
类型:ES7.x以上已经移除,类似于数据库中表的概念
文档:类似于数据库的行或者记录,以json格式存储
分片:为了实现水平扩展,索引会被水平分片,每个分片是独立的Lucene索引
映射:类似于数据库的表结构,定义了文档中字段的类型、分词器、是否索引等规则
倒排索引:词到文档的映射关系,(传统数据库是文档到词的正向索引)
# IK分词器
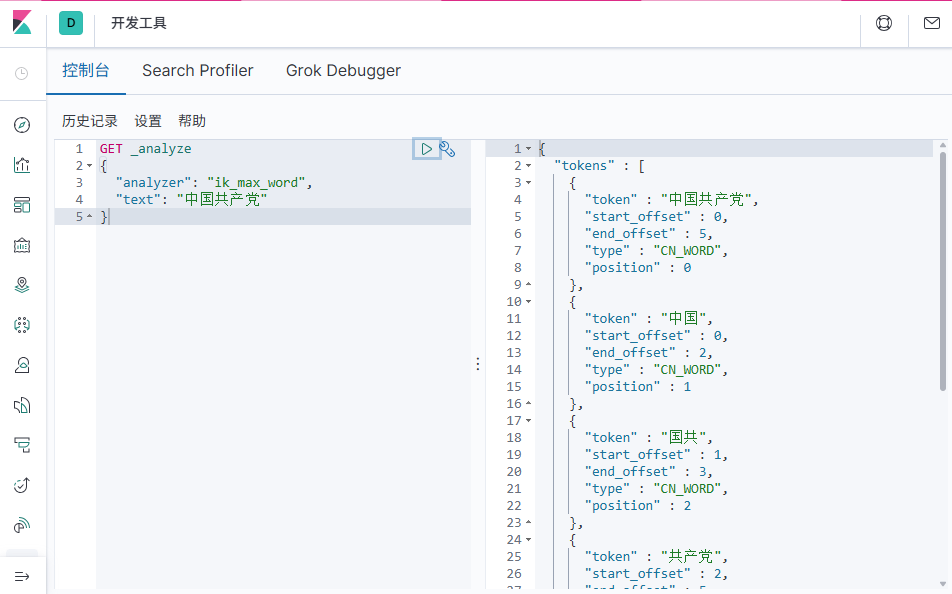
如果使用中文,建议使用IK分词器
IK提供了两个分词算法:ik_smart是最少切分,ik_max_word是最细粒度切分
# 安装
GitHub可以下载源码 https://github.com/infinilabs/analysis-ik
最新插件下载地址https://release.infinilabs.com/analysis-ik/stable/
下载对应版本zip后解压至plugins目录
重启es
1、执行命令查看已安装的插件
elasticsearch-plugin list

# 使用
1、测试ik_smart
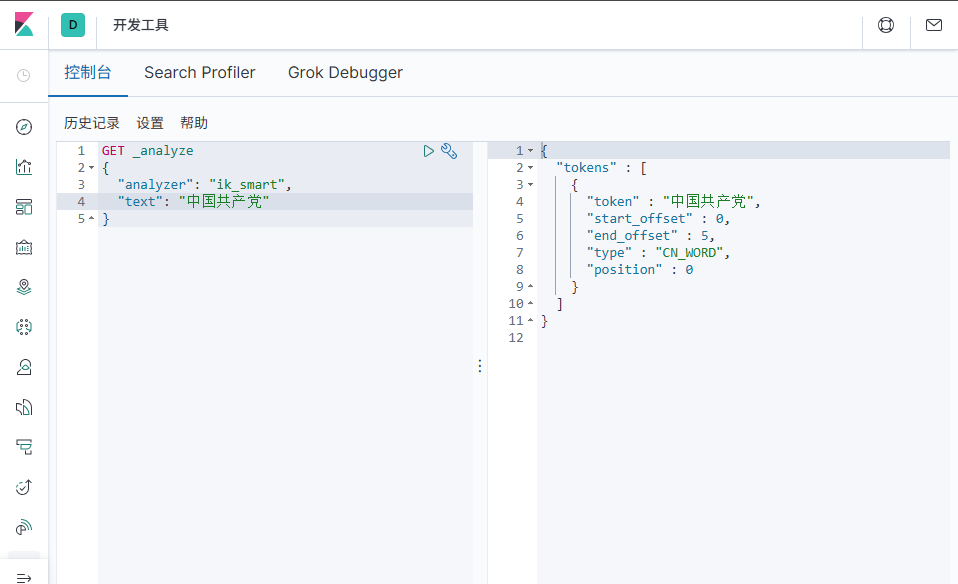
2、测试ik_max_word
# 分词器字典
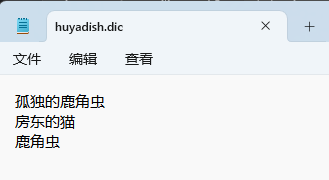
编辑自己的字典
编辑IKAnalyzer.cfg.xml配置文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">huyadish.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
重启es、 kibana
测试
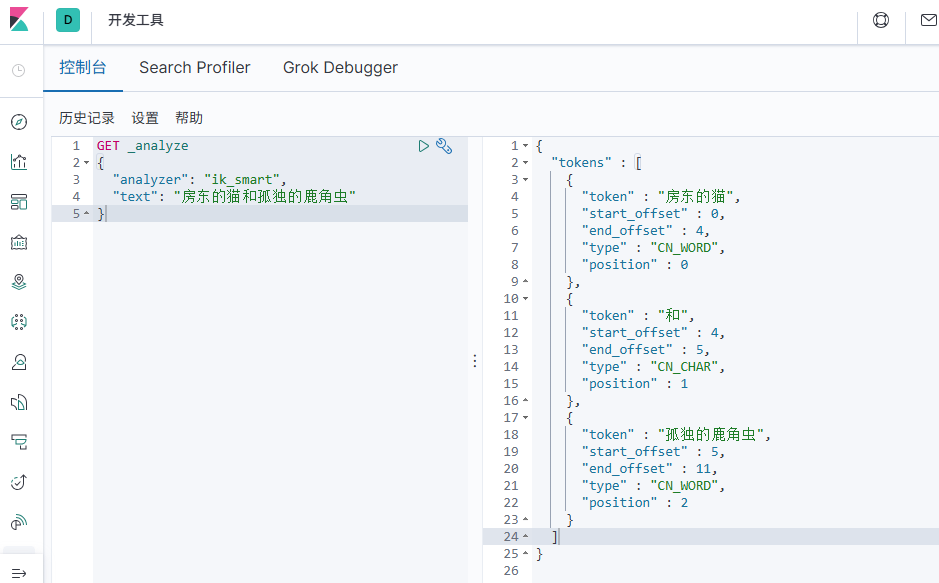
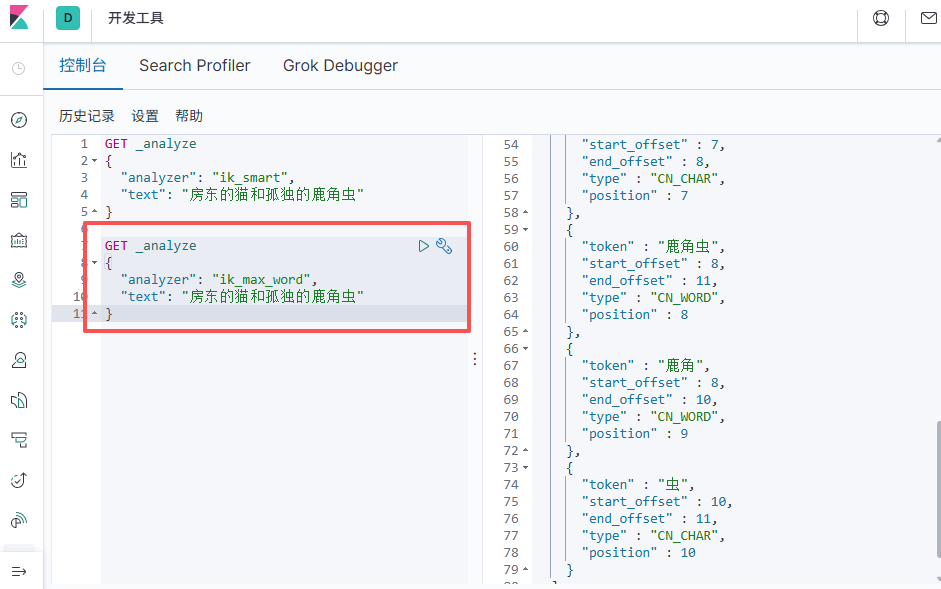
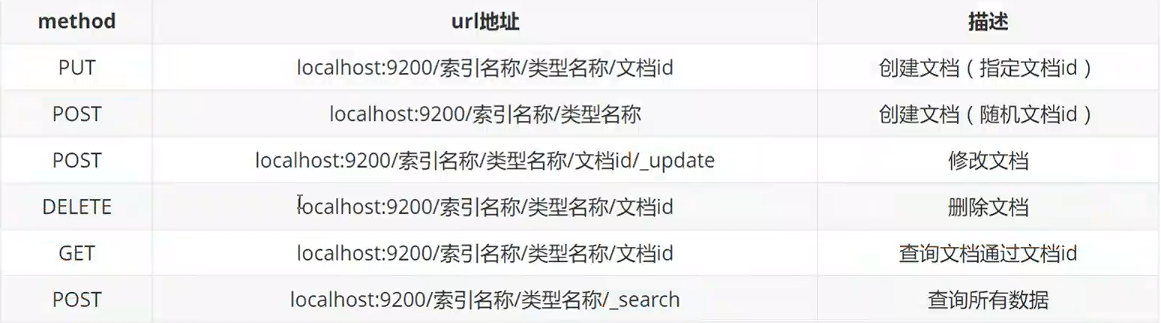
# Rest风格说明
# 创建索引
PUT /索引名/~类型名~/文档id
{请求体}
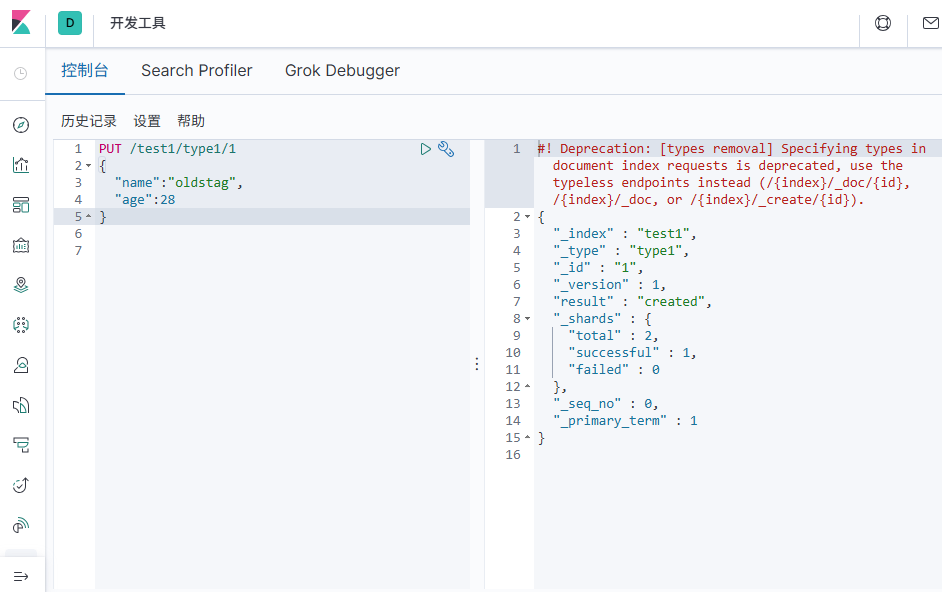
# 指定字段类型
创建索引和字段
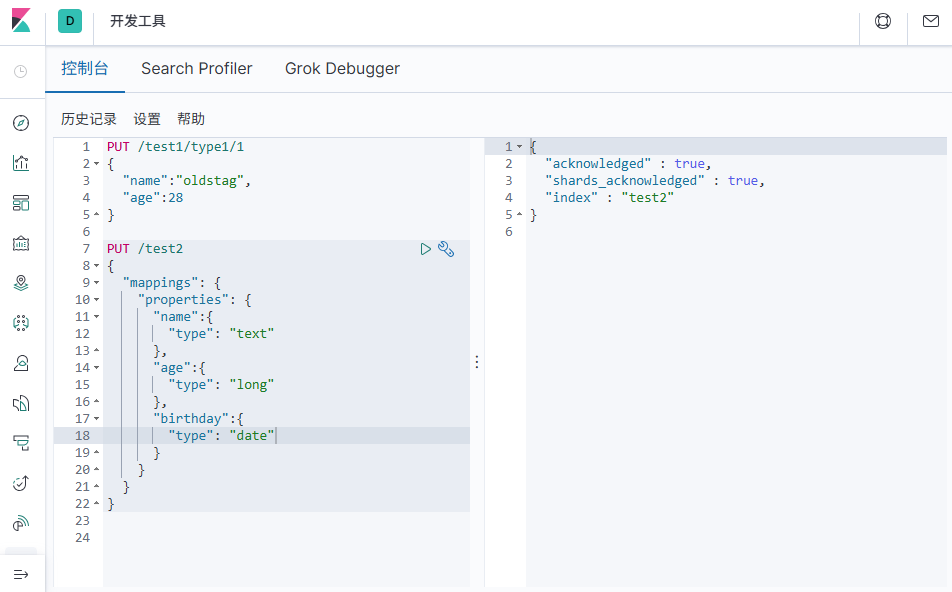
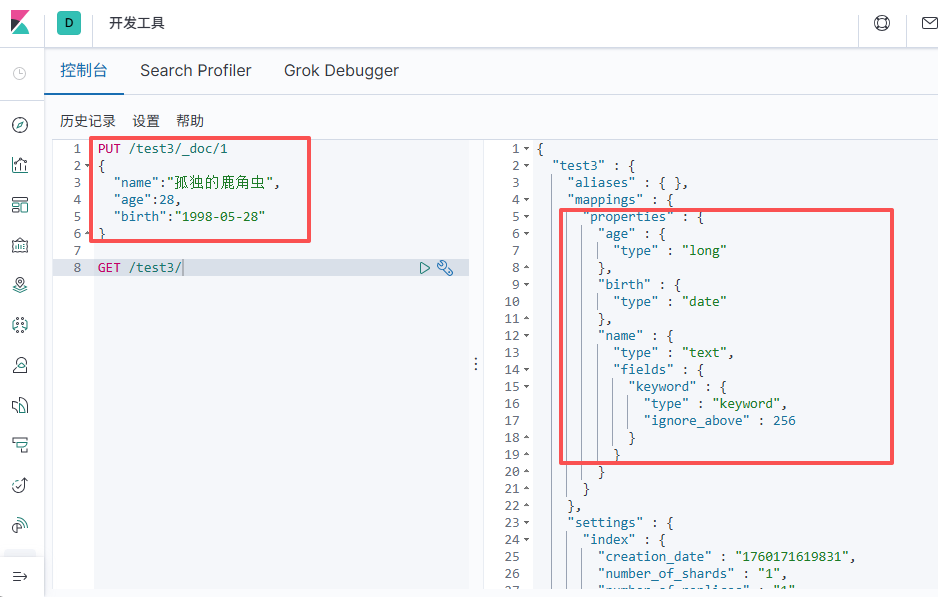
# 查询索引
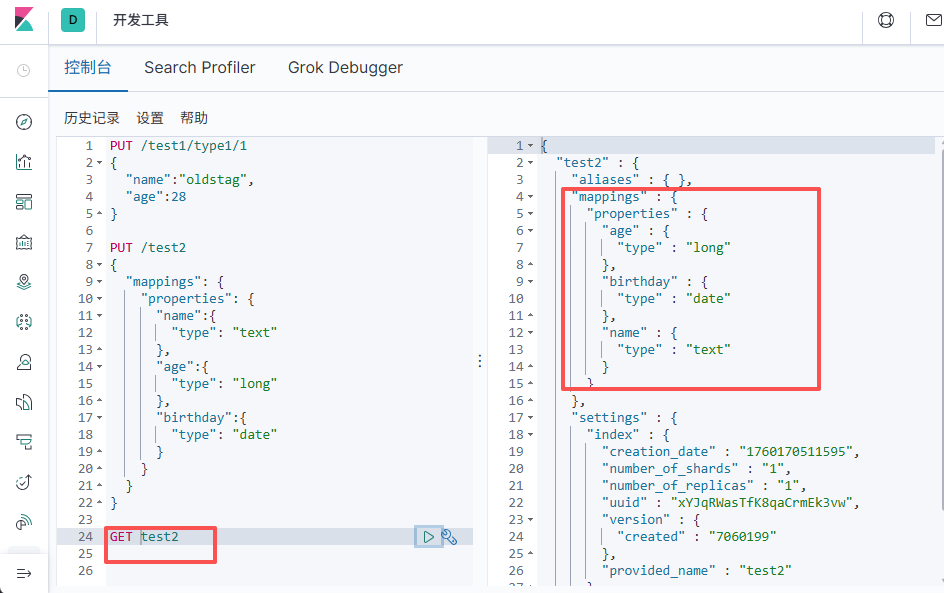
# 默认类型
创建索引,直接写入数据后,会有默认类型
# 遇到的问题
- 目录安装尽量不要用中文路径,或者空格,不要再用Program Files 了