# Java函数式编程
# 概述
为什么学?
- 大公司都在使用
- 大数据量下处理集合效率高
- 代码可读性高
# 函数式编程思想
面向对象思想关注用什么对象完成什么事情,而函数式编程思想类似于数学中的函数。它主要关注的是对数据使用了什么操作
优点:
- 代码简洁,开发迅速
- 接近自然语言,易于理解
- 易于并发编程
# Lambda表达式
Lambda是JDK8的一个语法糖,可以用于简化代码的编写
基本格式
(参数)->{方法体}
# 匿名内部类
函数式接口是指仅有一个抽象方法的接口,这样的接口可以隐式转换为lambda表达式
- 示例1:
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("新线程中run方法被执行了");
}
}).start();
// 使用Lambda表达式
new Thread(()->{
System.out.println("新线程2中run方法被执行了");
}).start();
- 示例2:
public static void main(String[] args) {
int i = calculateNum(new IntBinaryOperator() {
@Override
public int applyAsInt(int left, int right) {
return left + right;
}
});
System.out.println(i);
}
public static int calculateNum(IntBinaryOperator operator){
int a = 10;
int b = 20;
return operator.applyAsInt(a,b);
}
// 简化写法
int i = calculateNum((int left, int right) -> {
return left + right;
});
- 示例3
public static void main(String[] args) {
printNum(new IntPredicate() {
@Override
public boolean test(int value) {
return value%2==0;
}
});
}
public static void printNum(IntPredicate predicate){
int[] arr = {1,2,3,4,5,6,7,8,9,10};
for(int i : arr){
if(predicate.test(i)){
System.out.println(i);
}
}
}
// 简化写法
public static void main(String[] args) {
printNum(value -> value%2==0);
}
- 示例4:泛型方法
public static void main(String[] args) {
Integer i = typeConvert(new Function<String, Integer>() {
@Override
public Integer apply(String s) {
return Integer.valueOf(s);
}
});
System.out.println(i);
}
public static <R> R typeConvert(Function<String,R> function){
String str = "123456";
R result = function.apply(str);
return result;
}
// 简写
public static void main(String[] args) {
Integer i = typeConvert(s -> Integer.valueOf(s));
System.out.println(i);
}
- 示例5
public static void main(String[] args) {
foreachArr(new IntConsumer(){
@Override
public void accept(int value) {
System.out.println(value);
}
});
}
public static void foreachArr(IntConsumer consumer){
int[] arr = {1,2,3,4,5,6,7,8,9,10};
for(int i : arr){
consumer.accept(i);
}
}
// 简化
public static void main(String[] args) {
foreachArr(value -> System.out.println(value));
}
总结:
Lambda表达式是对匿名内部类的优化,只关注参数和方法体,将函数式接口的实现方法,交给函数去执行,类似于JS的箭头函数
# 省略规则
- 参数类型可以省略
- 方法体只有一句代码,大括号、return、和唯一一句代码的分号可以省略
- 方法只有一个参数时小括号可以省略
# Stream流
# 入门案例
// 打印所有年龄小于18的作家的名字,并且要注意去重
List<Author> authors = getAuthors();
authors
.stream() // 把集合转换为流
.distinct() // 先去除重复的作家
.filter(author -> author.getAge() < 18) // 筛选年龄小于18的
.forEach(author -> System.out.println(author.getName())); // 打印名字
# 创建流
// 单列集合 集合对象.stream()
List<Author> authors = getAuthors();
Stream<Author> stream = authors.stream();
// 数组 Arrays.stream() 或 Stream.of()方法创建
Integer[] arr = {1,2,3,4,5};
Stream<Integer> stream1 = Arrays.stream(arr);
Stream<Integer> stream2 = Stream.of(arr);
// 双列集合 转换为单列集合后再创建
Map<String,Integer> map = new HashMap<>();
map.put("安比",18);
map.put("胡桃",16);
map.put("八重樱",17);
Set<Map.Entry<String, Integer>> entries = map.entrySet();
Stream<Map.Entry<String, Integer>> stream3 = entries.stream();
# 中间操作
# filter
过滤流中的对象
// 打印所有姓名长度大于1的作家的姓名
authors.stream()
.filter(author -> author.getName().length() > 1)
.forEach(author -> System.out.println(author.getName()));
# map
对流中的对象进行计算或转换
// 打印所有作家的姓名
authors.stream()
.map(author -> author.getName())
.forEach(System.out::println);
# distinct
对流中的元素去重
// 去除重复的作家名称
authors.stream()
.distinct()
.forEach(author -> System.out.println(author.getName()));
注意:distinct()方法是依靠Object的
equals方法来判断是否是相同对象,所以需要注意重写的equals()方法
# sorted
对流中的元素进行排序
- 如果调用空参的sorted()方法,流中的对象需要实现
Comparable接口的compareTo方法
// 按年龄降序,并且不能有重复的元素
authors.stream()
.distinct()
.sorted()
.forEach(author -> System.out.println(author.getAge()));
public class Author implements Comparable<Author>{
private Long id;
private String name;
private Integer age;
private String intro;
private List<Book> books;
@Override
public int compareTo(Author o) {
return this.age-o.age;
}
}
- 使用有参数的sorted()需要实现自定义比较方法
// 按年龄降序,并且不能有重复的元素
authors.stream()
.distinct()
.sorted((o1, o2) -> o1.getAge()-o2.getAge())
.forEach(author -> System.out.println(author.getAge()));
# limit
取流的前n个元素,超出的部分会被丢弃
// 按年龄降序,并且不能有重复的元素,打印年龄最大的两个作家姓名
authors.stream()
.distinct()
.sorted()
.limit(2)
.forEach(author -> System.out.println(author.getName()));
# skip
跳过流的前n个元素,返回剩下的元素
// 打印除了年龄最大作家的其他作家,不能重复,按年龄降序
authors.stream()
.distinct()
.sorted()
.skip(1)
.forEach(author -> System.out.println(author.getName()));
注意:skip、limit可配合sorted使用
# flatMap
把一个对象转换成多个对象作为流中的元素
- 示例1
// 打印所有书籍的名字,对所有重复书籍进行去重
authors.stream()
.flatMap((Function<Author, Stream<?>>) author -> author.getBooks().stream())
.distinct()
.forEach(System.out::println);
可以通过IDEA的断点debug,和流跟踪的功能查看具体的转换过程,还是很形象的
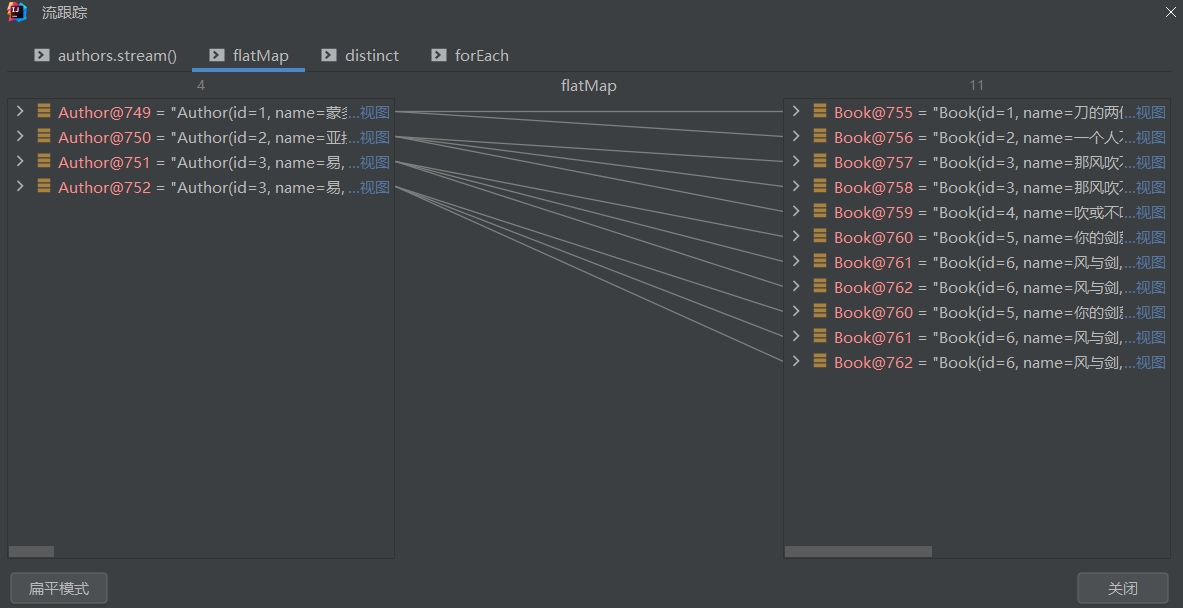
- 示例2
// 打印所有书籍的名字,对所有重复书籍进行去重
authors.stream()
.flatMap( author -> author.getBooks().stream())
.distinct()
.flatMap( book -> Arrays.stream(book.getCategory().split(",")))
.distinct()
.forEach(System.out::println);
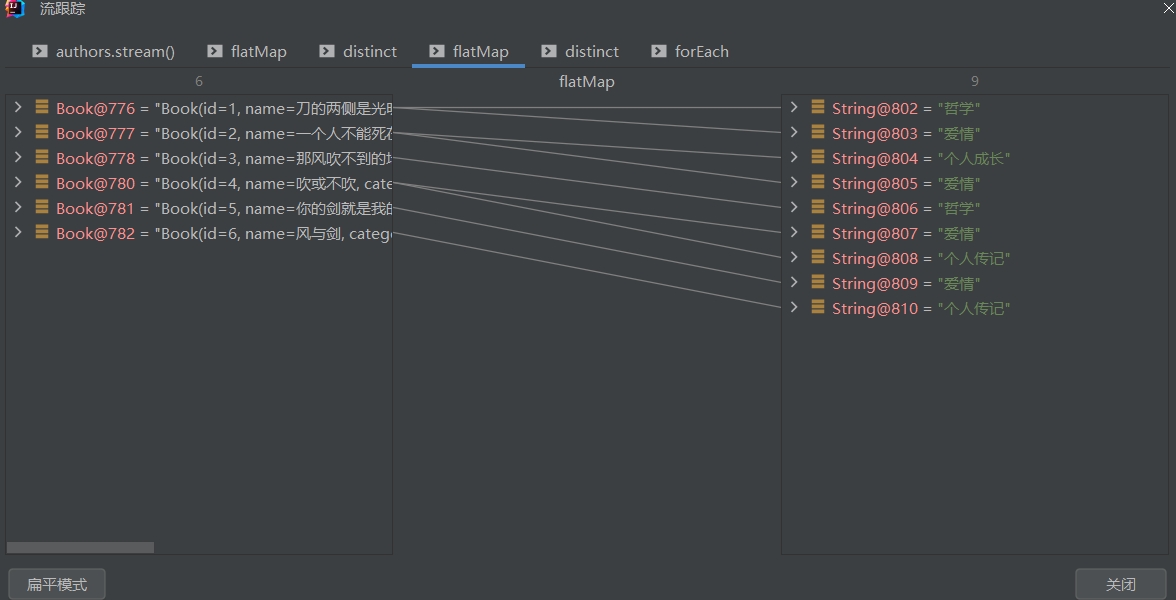
# 终结操作
# forEach
对流的元素进行遍历
// 输出所有作家名字
authors.stream()
.distinct()
.forEach(author -> System.out.println(author.getName()));
# count
获取当前流中元素的数量
// 输出所有作家所出书籍的数目
long count = authors.stream()
.flatMap(author -> author.getBooks().stream())
.distinct()
.count();
System.out.println(count);
# max&min
获取流中元素的最值,会返回一个Optional对象
// 输出所有书籍的最高分和最低分
Optional<Integer> max = authors.stream()
.flatMap(author -> author.getBooks().stream())
.map(book -> book.getScore())
.max((o1, o2) -> o1 - o2);
Optional<Integer> min = authors.stream()
.flatMap(author -> author.getBooks().stream())
.map(book -> book.getScore())
.max((o1, o2) -> o2 - o1);
System.out.println(max.get());
System.out.println(min.get());
# collect
collect用于将结果收集为集合,传入Collectors的静态方法
// 获取作者名字的list集合
List<String> collect = authors.stream()
.map(author -> author.getName())
.collect(Collectors.toList());
// 获取所有书名的set集合
Set<String> collect1 = authors.stream()
.flatMap(author -> author.getBooks().stream())
.map(book -> book.getName())
.collect(Collectors.toSet());
// 获取一个Map集合,key为作者名,value为books集合, key不能重复
Map<String, List<Book>> collect2 = authors.stream()
.distinct()
.collect(Collectors.toMap(author -> author.getName(), author -> author.getBooks()));
# 查找与匹配
方法的参数类型都是 java.util.function.Predicate,这个接口只有一个方法,就是test()
返回值为Boolean:
anyMatch:有任意一个匹配
allMatch:所有都匹配
noneMatch:都不匹配
返回值为Optional:
- findAny:获取任意一个
List<Author> authors = getAuthors();
Optional<Author> any = authors.stream()
.filter(author -> author.getAge() > 40)
.findAny();
any.ifPresent(author -> System.out.println(author.getName()));
- findFirst:获取第一个
// 找到年龄最小的
Optional<Author> first = authors.stream()
.sorted((a1,a2)->a1.getAge()-a2.getAge())
.findFirst();
first.ifPresent(author -> System.out.println(author.getName()));
# reduce双参数
双参数的重载形式,第一个参数是初值,第二个参数是累计操作函数
内部实现如下
T result = identity;
for (T element : this stream)
result = accumulator.apply(result, element)
return result;
案例:
// 年龄求和
Integer sum = authors.stream()
.map(author -> author.getAge())
.reduce(0, (prev, cur) -> prev + cur);
// 最大年龄
Integer maxAge = authors.stream()
.distinct()
.map(author -> author.getAge())
.reduce(Integer.MIN_VALUE, (prev, cur) -> prev > cur ? prev : cur);
// 最小年龄
Integer minAge = authors.stream()
.distinct()
.map(author -> author.getAge())
.reduce(Integer.MAX_VALUE, (prev, cur) -> prev < cur ? prev : cur);
说明:
初值和返回值类型是相同的,所以可以先map进行类型转换
# reduce单参数
内部实现
boolean foundAny = false;
T result = null;
for (T element : this stream) {
if (!foundAny) {
foundAny = true;
result = element;
}
else
result = accumulator.apply(result, element);
}
return foundAny ? Optional.of(result) : Optional.empty();
案例
Optional maxAge = authors.stream()
.distinct()
.map(author -> author.getAge())
.reduce((prev, cur) -> cur > prev ? cur : prev);
# 注意事项
- 惰性求值(如果没有终结操作,中间操作是不会得到执行的)
- 流是一次性的
- 不会影响原数据(正常使用情况下)
# Optional
# 概述
Optional是JDK8引入的新特性,可以把具体数据封装到Optional中,然后使用Optional中封装好的方法操作数据,用于优雅地解决空指针异常问题
# 创建对象
- 当不确定一个对象是否为空时,使用
Optional.ofNullable()
// 以前需手动判断对象是否为空
public static void main(String[] args) {
Author author = getAuthor();
if(author != null){
System.out.println(author.getName());
};
}
public static Author getAuthor(){
Author author = new Author(1L, "胡桃", 16, "吃好喝好,一路走好", null);
return author;
}
// 现在通过Optional
public static void main(String[] args) {
Optional<Author> author = getAuthor();
author.ifPresent(author1 -> System.out.println(author1.getName()) );
}
public static Optional<Author> getAuthor(){
Author author = new Author(1L, "胡桃", 16, "吃好喝好,一路走好", null);
return Optional.ofNullable(author);
}
- 当确定一个对象不是空的时候,可以使用Optional.of()
Author author = new Author();
Optional<Author> optional = Optional.of(author);
- 当确定一个对象为空时,可以使用Optional.empty()
Optional.empty();
总结:
无脑用Optional.ofNullable()
Mybatis3.5版本支持返回Optional
# 安全消费值
ifPresent()方法
Optional<Author> authorOptional = getAuthor();
authorOptional.ifPresent(author -> author.getName());
# 安全获取值
orElseGet()和orElseThrow()方法
Optional<Author> authorOptional = getAuthor();
// 没有值是返回默认值
Author author1 = authorOptional.orElseGet(() -> new Author(1L, "胡桃", 16, "吃好喝好,一路走好", null));
// 没有值时抛出异常
Author author2 = authorOptional.orElseThrow(() -> new RuntimeException("数据为null"));
# 过滤
用filter()方法对元素进行过滤,如果原本是有数据的,但是不符合判断条件,也会返回一个无数据的Optional对象
authorOptional.filter(author -> author.getAge()>100).ifPresent(author -> System.out.println(author.getName()));
# 判断
isPresent()判断是否存在输出,不常用
# 数据转换
Optional还提供了map可以让我们的对数据进行转换,并且转换得到的数据也还是被Optional包装好的,保证了我们的使用安全。
Optional<Author> authorOptional = getAuthor();
Optional<List<Book>> books = authorOptional.map(author -> author.getBooks());
books.ifPresent(books1 -> System.out.println(books1));
# 函数式接口
# 常见函数式接口
- Consumer 消费接口 例如forEach方法
- Function 计算转换接口 例如map方法
- Predicate 判断接口 例如filter方法
# 函数式接口的默认方法
and
authors.stream()
.filter(((Predicate<Author>) author -> author.getAge() > 17)
.and(author -> author.getName().length()>1))
.forEach(author -> System.out.println(author.getName()+"---"+author.getAge()));
or
authors.stream()
.filter(((Predicate<Author>) author -> author.getAge() > 25)
.or(author -> author.getName().length() == 1))
.forEach(author -> System.out.println(author.getName()+"---"+author.getAge()));
negate 表示对前面的条件取反
authors.stream()
.filter(((Predicate<Author>) author -> author.getAge() > 20).negate())
.forEach(author -> System.out.println(author.getName()));
# 方法引用
在使用lambda表达式时,如果方法体只有一个方法的调用的话,可以用方法引用进一步简化代码。属于一个语法糖
基本格式:类名或对象名::方法名
# 类的静态方法
重写方法的所有参数按顺序传入类的静态方法中
List<Author> authors = getAuthors();
Stream<Author> authorStream = authors.stream();
// 优化前 age传给了String.valueOf(age)
authorStream.map(author -> author.getAge())
.map(age->String.valueOf(age));
// 优化后
authorStream.map(author -> author.getAge())
.map(String::valueOf);
# 对象的实例方法
重写方法的所有参数按顺序传入对象的实例方法中
List<Author> authors = getAuthors();
Stream<Author> authorStream = authors.stream();
StringBuilder sb = new StringBuilder();
// 优化前 author.getName()没有传入author参数,不能简化 sb.append(name)可以简化
authorStream.map(author -> author.getName())
.forEach(name->sb.append(name));
// 优化后
authorStream.map(author -> author.getName())
.forEach(sb::append);
# 类的实例方法
调用了第一个参数的成员方法,并且重写方法的剩余参数按顺序传入类的实例方法中
interface UseString{
String use(String str,int start,int length);
}
public static String subAuthorName(String str, UseString useString){
int start = 0;
int length = 1;
return useString.use(str,start,length);
}
public static void main(String[] args) {
subAuthorName("rong", new UseString() {
// 这里用匿名内部类的方式实现类UseString接口
@Override
public String use(String s, int beginIndex, int endIndex) {
// 调用了第一个参数s的成员方法subString ,同时 beginIndex,endIndex传给了subString方法
return s.substring(beginIndex, endIndex);
}
});
}
// 可以简化为
public static void main(String[] args) {
subAuthorName("rong", String::substring);
}
注意:所谓的第一个参数去调用,通常就是累的实例对象
# 构造器
调用了某个类的构造方法,并且把并且重写方法的所有参数按顺序传入构造方法中
authors.stream()
.map(author -> author.getName())
.map(name->new StringBuilder(name))
.map(sb->sb.append("-三更").toString())
.forEach(str-> System.out.println(str));
// 优化后
authors.stream()
.map(Author::getName) // 类的实例方法
.map(StringBuilder::new) // 构造器
.map(sb -> sb.append("-三更").toString()) // 多行代码无法转换
.forEach(System.out::println); // 类的实例方法
小结:
- 类的实例方法的方法引用,要求(匿名内部类)的重写方法的第一个参数,去调用这个实例方法,并且把剩余参数传入
- 其他的都要求把所有的参数传入
# 高级用法
# 基本数据类型优化
流中大量数据的自动装箱和拆箱操作,比较耗时,Stream提供了针对基本数据类型的优化方法
如:mapToInt,mapToLong,mapToDouble,flatMapToInt,flatMapToDouble等等
authors.stream()
.map(author -> author.getAge())
// 流后面的操作是返回值都是Integer类型
.map(age -> age + 10)
.filter(age -> age > 10)
.map(age -> age + 2)
.forEach(System.out::println);
authors.stream()
.mapToInt(author -> author.getAge())
// 优化后是都是int类型
.map(age -> age + 10)
.filter(age -> age > 10)
.map(age -> age + 2)
.forEach(System.out::println);
# 并行流
stream.parallel()方法可以把串行流转换成并行流
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
Integer sum = stream
// 中间方法,用于调试,并不会真的消费掉数据
.peek(new Consumer<Integer>() {
@Override
public void accept(Integer num) {
// 查看当前处理数据的线程
System.out.println(num+Thread.currentThread().getName());
}
})
.filter(num -> num > 5)
.reduce((result, ele) -> result + ele)
.get();
System.out.println(sum);
也可以使用parallelStream()方法直接获取并行流对象
← Java从入门到精通 Java常用类库 →